

tl;dr
Christopher Fleetwood presents Ratchet and shares some exciting news | WebGPU becomes mainstream (ONNX, transformer.js) | Burn gets JIT kernel fusion | WASM build of llama.cpp | Tiny transformer from scratch
Table of Contents
AI conversations
Christopher Fleetwood on Ratchet
Christopher is a ML engineer at HuggingFace and best known for his work on whisper-turbo. On Tuesday we interviewed him over Discord on his latest project, exciting news he got to share and future trends in web AI.
Jan: Christopher, great to have you here. Maybe we can start off by telling us a few words about yourself, what you do and what got you into ML.
Christopher: Hey Jan,
I've been an engineer at Huggingface for ~2 months now, primarily focused on Ratchet, which is a cross-platform ML runtime written from the ground up in Rust.
I started working on ML at university, doing research on machine learning models for neuroscience, primarily focused on dementia & predicting cognitive impairment. During that time I wrote some Rust code to speed up some slow Python scripts we had for distance metrics for fMRI scans, and I've been hooked ever since!
J: Very cool! Last year you published whisper-turbo which gained quite a bit of publicity. What made you start whisper-turbo and what were the challenges you were facing?
C: Whisper-Turbo came out of a desire to build real time speech to text (it's pretty sci fi stuff if you can get it to work & build an LLM into the loop). It was my most challenging technical project to date, as I had to write all the kernels by hand in the WebGPU shading language to make it run in the browser. Quantization in particular poses a ton of challenges, particularly when you only have 32 bit floats.
J: Some of our readers are probably not yet familiar with WebGPU. Could you tell us a bit more about what it is and why this is such an exciting development in Web AI.
C: WebGPU is a pretty awesome graphics API that google has been working on for about 7 years. It finally makes compute a first class citizen on the web, as opposed to all the previous APIs that were designed for graphics like WebGL. The "Web" in WebGPU is also a bit of a misnomer, it's pretty much just a cross platform API for programming your GPU. Write once, run anywhere.
J: Tell us a bit about your latest project Ratchet which specifically targets WebGPU! What is your goal with it and where are you right now?
C: Ratchet is the culmination of a good amount of work in the Rust + WebGPU space. I want to build a toolkit for developers to integrate on-device ML into their projects. We are still pretty early, but we have strong support for Whisper & quantization out of the box. In the future, we are looking to be a complete package for users, this means:
A database to manage your on-device models
Wide range of model support
Speculative decoding with a cloud based "main model" and a local "draft model"
J: Today you also got some amazing news to share together with the distil whisper team. Tell us about it!
C: Yes! Coming 21st March distil-whisper-large-v3 is launching! This model is distilled from the latest OpenAI whisper release. Benchmarks will be released soon, but the performance is very impressive from our testing. Ratchet will support distil-whisper-large-v3 on day 1, and you can try it out on a HF space on launch day 🚀
J: Super exciting, can't wait to give it a try! Coming back to the details of ratchet: What makes Ratchet different from other web ml frameworks like transformers.js or web-llm?
C: Transformers.js runs on ONNX Runtime Web, which is a Microsoft project. ONNX Runtime Web is a great project, but there are a few design decisions made early on, that are baked in now. Machine Learning models have evolved massively since ORT was started, and it seems wise to start again with all of the knowledge we have now.
Web-LLM is a great project powered by TVM, which is a really innovative ML compiler. However, TVM is a huge amount of C++, and their main focus isn't really on WebGPU, but more their other backends. I'm hoping that a rewrite in Rust will be more accessible to the community, and we can narrow our scope in order to exceed their performance.
J: What made you choose Rust as language for the web? What are in your opinion advantages and disadvantages in comparison to typescript or javascript?
C: I think Rust has absolutely state of the art WASM support, and JS integration tooling. If we look at tooling in the web development world, we've seen a massive shift in the past few years from traditional JS/TS tooling to big rewrites in Rust. Companies like Vercel and others have shifted their entire stack onto Rust, and the bet seems to be paying off.
J: Tell us a bit about your roadmap for ratchet for the coming months, what are your goals, what can we expect?
C: I think some key milestones for Ratchet coming up are:
First Alpha release where people can actually start using our stack.
Model support: I’d like to push support for at least the key on-device models like Phi2, XTTS, code models etc.
Seamless speculative decoding: This is something I haven’t really seen anyone push to its limit, but I think there is a huge opportunity to reduce costs using speculative decoding.
A personal goal of mine is to start our Just-In-Time compiler to get SOTA performance!
J: Are you still looking for contributors and if so, how can someone help? Do you need to have a PhD in ML to contribute?
C: Yes! I'm really hoping the community finds the project interesting and wants to help out! Having a PHD in ML is absolutely not required, but some Rust knowledge might help you before you start out!
J: What do you think AI in the web will look like in five years? What trends do you see coming up?
C: I think we will see AI proliferate into every facet of the stak. And I always say "don't bet against the web". There is a ton of interesting work being done (like the WebNN group), expect to see big growth in this area!
J: Christopher, thank you very much for your time and all the best for your future!
C: Thank you!!
Latest developments
ONNX Runtime Web supports WebGPU
Probably the most eagerly awaited release has been the integration of WebGPU into Microsoft’s ONNX Runtime Web. Read the full story here:
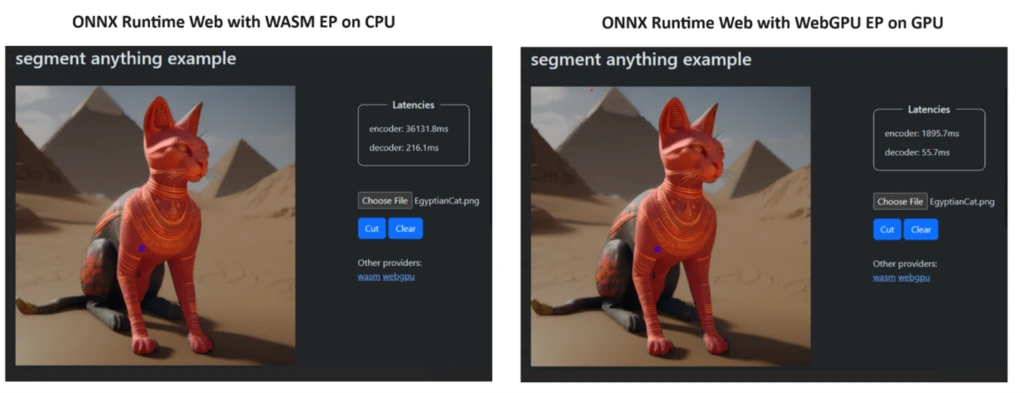
Transformers.js supports WebGPU
Transformers.js - which is built on ONNX Runtime Web - follows suit and integrates the new WebGPU backend. While the official release is scheduled for the upcoming v3 version, the first benchmarks look really promising and Joshua conveniently provided a benchmark that you can try yourself (in Chrome, Edge or Firefox Nightly):

When running it I got ~40x speed up vs the plain WASM version, pretty impressive!

Burn gets JIT backend
The burn framework recently merged a new backend for JIT kernel fusion that can drastically improve performance. They also wrote an excellent blog post about it:

If you are interested in learning more, Christopher pointed me to an interesting paper where this concept is described in more detail.
Also burn introduced a new web site, pretty sleek if you ask me. Check it out athttps://burn.dev.
Tangled group publishes WASM build of llama.cpp
Tangledgroup has published a WASM build of llama.cpp with a live demo at https://llama-cpp-wasm.tangledgroup.com/
Even though this doesn’t support WebGPU it runs surprisingly fast. While I think the general direction is WebGPU, I still think this is pretty cool and has a few advantages:
Runs on browsers that don’t support WebGPU yet like Safari or Firefox
Supports the widely used GGUF file format
Supports 4-bit quantisation out of the box
Worth reading
The making of Minueza-32M: Transformer model trained from scratch by Victor Nogueira
Victor focuses on small models for the web and wrote a very nice step-by-step guide to that led him to the training of Minueza-32M model.
CHANGELOG.md
ONNX Runtime web 1.17.0 released - Adds WebGPU support
Transformers.js 2.16.1 released - Adds support for
image-feature-extractionpipeline, EfficientNet and moreTransformers.js 2.16.0 released - Adds StableLM models support and more
On our own behalf
Are you working on a cool project with AI in the browser that you’d like to share? I’d be especially interested in art projects using AI in the browser. Send us an email to [email protected].